
RAG to Reality: What is Retrieval-Augmented Generation ?
This blog series is a longer format and expansion of my UK Oracle User Group presentation, titled; RAG to Reality: A deep-dive into enhancing AI with Retrieval-Augmented Generation, as well as the Oracle published blog: RAG to reality: Amplify AI and cut costs. A mouthful! But an accurate description.
A brief overview of what we'll cover in this series!
- What is Retrieval-Augmented Generation (Part1) - [This Blog]
- Use-cases
- Retrieval-Augmented Generation (RAG) Definition
- Basic RAG Architecture
- RAG Enhancements
- Oracle Cloud Infrastructure (OCI) Artificial Intelligence (AI) Services (Part2)
- OCI AI RAG Architectures (Part3)
- Easy Demo Build Guide (Part4)
- Advanced RAG (Part5)
Use-Cases
Before we even get into the details of Retrieval-Augmented Generation (RAG), lets see the type of scenario that brings about the need for RAG.
In the above scenario, HR spend an egregious amount of time dealing with employee queries since; policies are stored across different locations (contracts stored in HCM, benefits stored in a 3rd party site etc) and different parts of the business have entirely different policies (due to mergers & acquisitions). So there is not a one size fits all answer to most given queries!
Other scenarios may include;
- Customer Support: A need to provide real-time, accurate answers based upon policy documents
- Healthcare: Summarise patient records and retrieve relevant clinical guidelines
- Legal Tech: Extracting relevant case laws from large repositories for litigation support
- Financial Analysis: Summarising market trends and retrieving regulatory data
- Academic Research: Providing Summaries of related studies and findings across journals
Solving the problem
The features of GenAI & LLMs seem to be the right fit!
But if we ask ChatGPT 'how many days of annual leave am I entitled to?', it will give you a generic, long-winded answer. It's not trained on our enterprise data and it doesn't have access to our proprietary information such as our policies. Therefore, it can never give a precise and concise answer. So how do we go from a generic response, to a precise response ?
There are 3 main options here, but the most efficient of them all is Retrieval-Augmented Generation. So we finally get to it! So, what is RAG?
Retrieval-Augmented Generation
It's in the name!
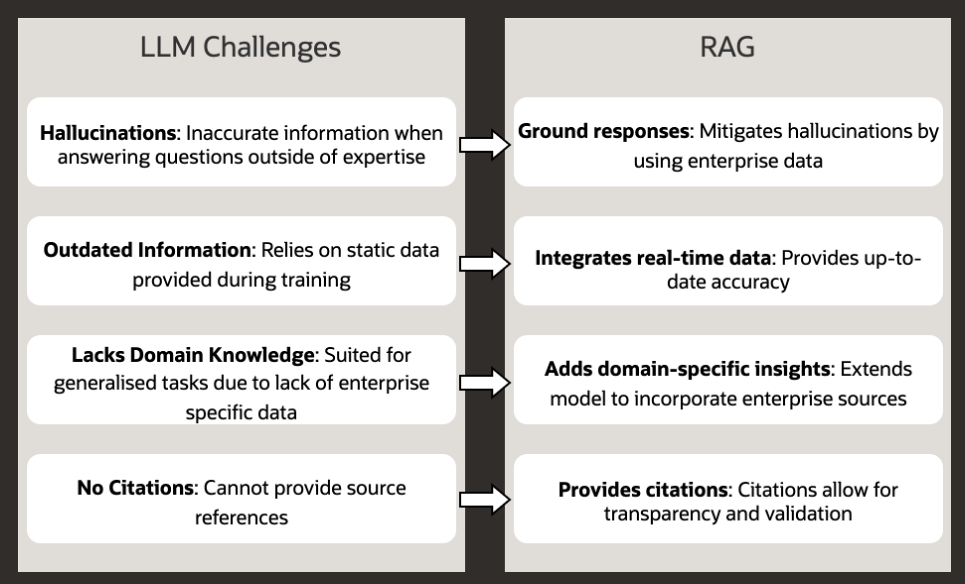
RAG is a framework that (1) Retrieves relevant, context-specific data from a knowledge-base in real-time, (2) augments the LLMs input with this retrieved data to (3) generate a response that is informed, contextually accurate and grounded upon up-to-date data. Easy-peasy! This framework addresses some of the key challenges you find with off the shelf LLMs
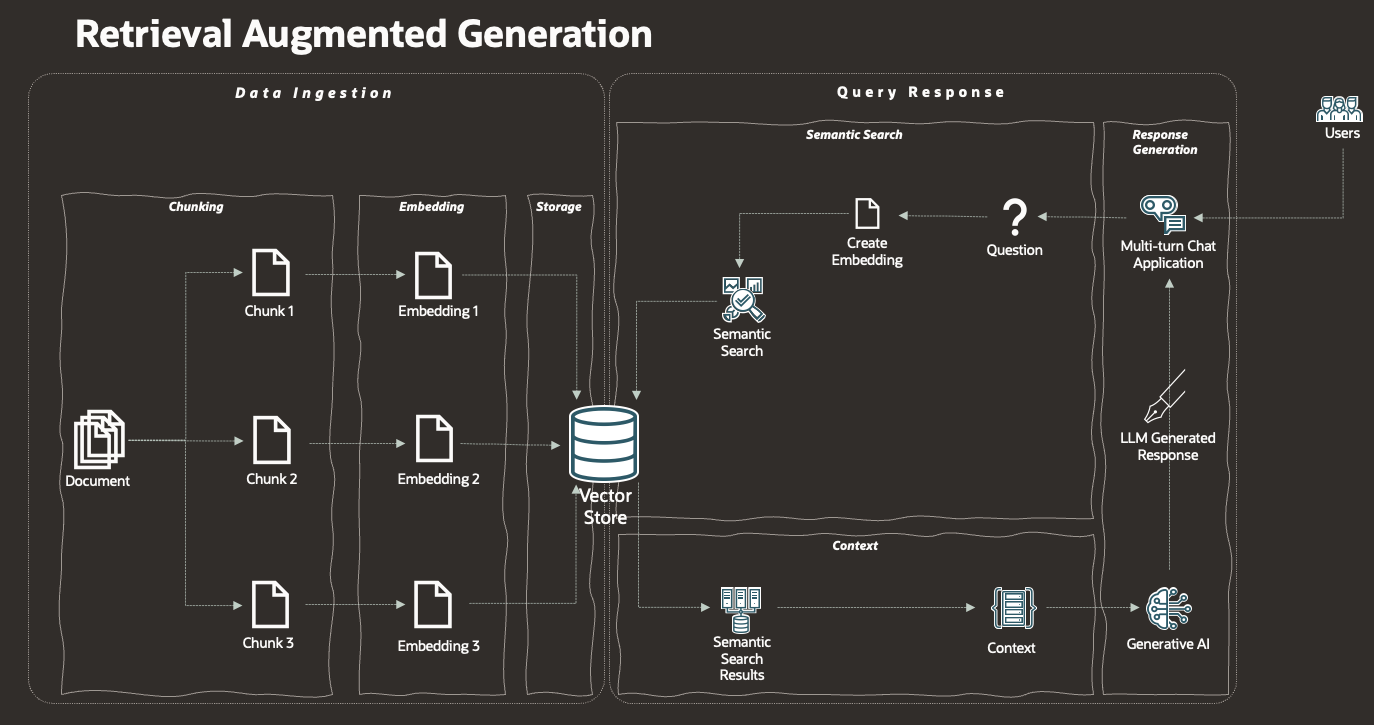
So now let's look at an actual (basic) RAG architecture!
For ease of understanding, let's split this into 2 sections; Data Ingestion and Query Response.
Data Ingestion
Data Ingestion has 3 main steps.
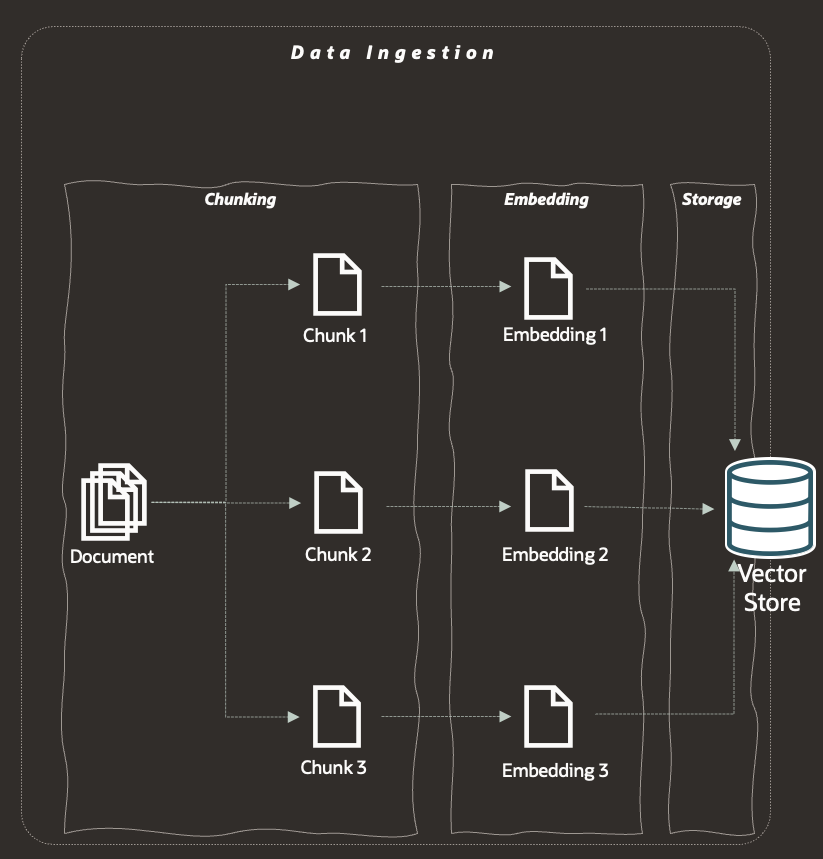
- Chunking
Chunking is the process of dividing the corpus of documents into smaller text segments. It is required due to LLMs having a limit on the amount of data, typically measured in tokens, that it can in-take in any given call. So we split large texts into smaller segments, but an issue arrises when a given chunk doesn't capture an entire thought or idea.
In the RAG process, we will retrieve 'chunks' based on a similarity search and it is these chunks that will be passed into the LLM. So if a 'chunk' ends part-way through a thought, it may result in an incorrect conclusion as you are reading only part of an idea and you do not have the context in which to understand the given matching phrase in the chunk. How do we overcome this ? One popular method is overlapping; we overlap chunks such that a given text segment may be included in more than 1 chunk, this increases the chances of an entire thought or idea being captured in a single chunk. A more advanced technique is to use to use context-aware chunking in which an NLP model can be utilised to create semantic coherent chunks.
- Embedding
Embedding is the process of transforming these text chunks into vectors, using an embedding model.

Embedding models are specially trained algorithms that convert the original data into a vector, whilst encapsulating information, features/properties of the original data in the vector. A vector consists of a list of numbers, each number is referred to as a dimension, and the dimensions capture the semantic meaning of the original word(s)/sentence(s) (when embedding text). The above image is a massive over simplification, but it is illustrating the idea that vectors are indeed a numeric representation of the information & features of the original data. Vectors will be discussed in more detail in 'Semantic Search' section
- Vector Store
A vector store is just that, a store of all of the vectors. Vector stores are designed for low-latency retrievals and searching, whilst providing scalability and integration with popular ML pipelines for large-scale deployments
Query Response
Interacting with a RAG system (asking a question), and getting a response back, involves 5 key steps;
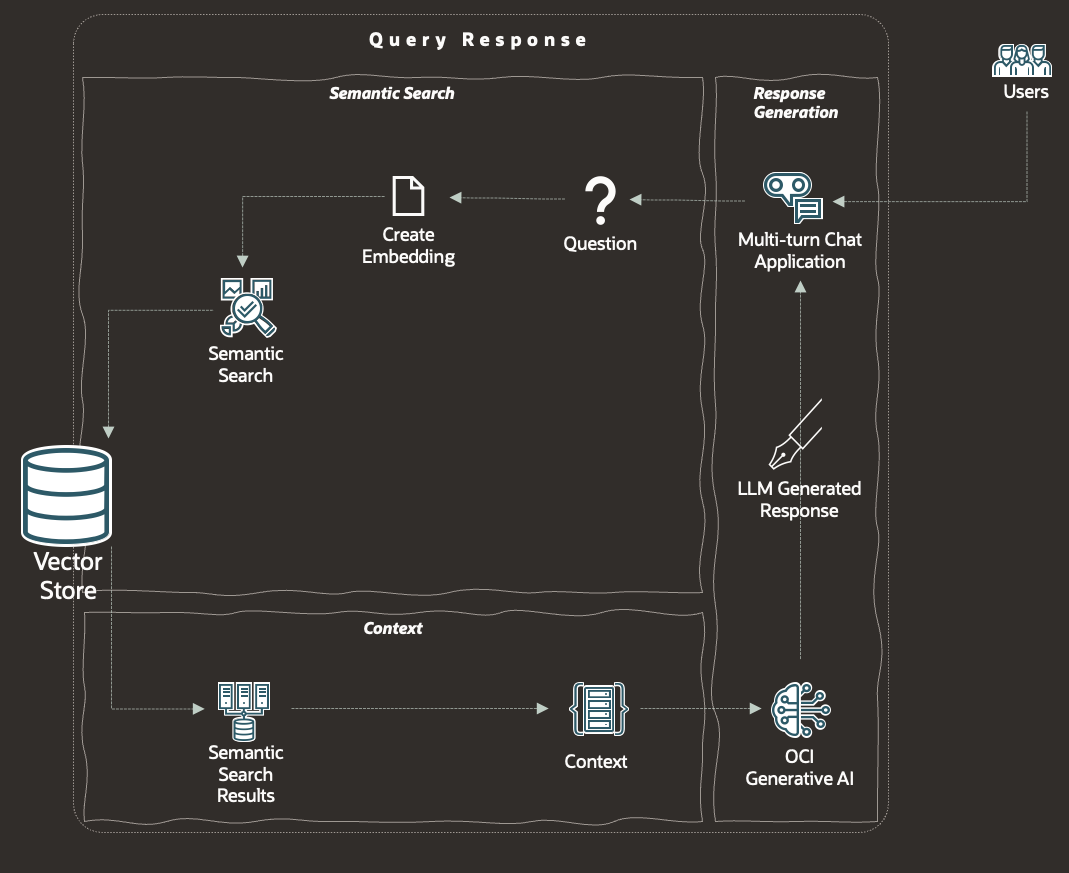
- Question to RAG System
We require an entry point into our RAG system which, in the diagram, is the 'Multi-turn Chat Application'. It is worth noting, that both for data ingestion and query response, there several steps required, as such we require an orchestrator or co-ordinator, which isn't depicted in this basic RAG diagram. We'll highlight this further in the 3rd blog in this series.
- Embed Question
The original question is embedded (converted to a vector), which will allow us to search against our vector store to find semantically similar documents. Embedding has already been covered in Data Ingestion.
- Semantic Search
We then use the embedded question to execute an semantic search and identify the closest matching document chunks (which in theory will answer our question). The results of the semantic search will be an input into the LLM. But what exactly is semantic search ?
To try and avoid the philosophical debate about semantic search and vector similarity search, I will simply say that vector search is a part of a multi-step process to implement semantic search. Vector search refers to finding closely related data, in terms of semantics or features, by comparing the distance or angle of their vectors.
To understand this better, we'll base our example on Euclidean distance. Lets take the vector representation of a series of words and plot them onto a graph. The position of each word is represented by their respective vectors and through this we can visually see how closely related words are positioned close together. (In reality, the actual vectors would be hundreds of dimensions and the vectors would be plotted in a Euclidean space consisting of n-spaces, with n being the number of dimensions in a given vector. But for visual purposes, we'll represent them in 2 dimensions).
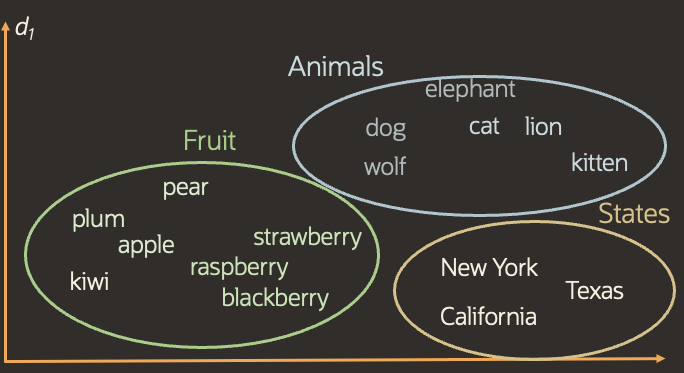
A raspberry is very similar, in terms of semantics and features, to a blackberry and therefore they are positioned close together. A blackberry has quite different properties to a plum, but they are still related in the sense that both are fruits, as such they fall within the vicinity of all fruits. But a plum is very different to an elephant, so their vectors are of great distance.
So if we take a new word, we can find the closest matching words by simply comparing its vectors to the vectors in the series and seeing which is the closest.
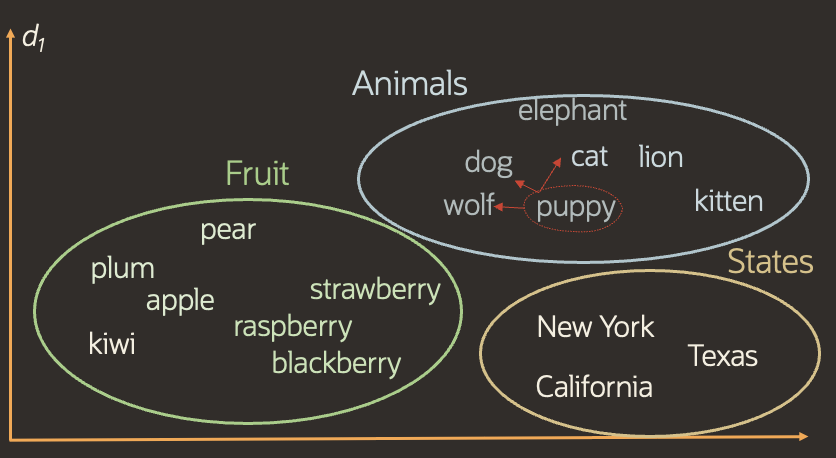
So if we insert the word puppy, we can see that dog, cat and wolf are the closest. But how do we do this mathematically ? We simply apply a formula to compare 2 vectors, the output being a single digit which numerically represents the distance between 2 given vectors.
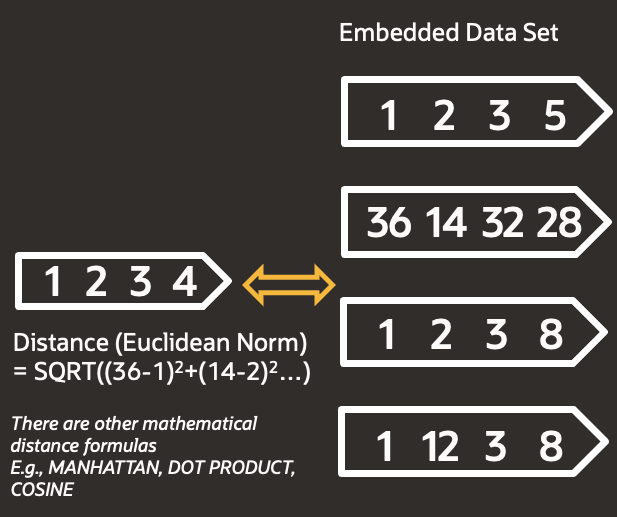
The above example measures the euclidean distance between 2 vectors (derived from Pythagoras theorem), but there are many other formulas we can use. We simply;
- Calculate the difference between our 2 vectors over a given dimension
- Square this number (this way we always work with a positive number and escape the void of imaginary numbers when square-rooting)
- Do the above for all dimensions, and sum all outputs
- Square root the sum to produce a single number which represents the distance of 2 vectors.
Simply by looking at the numbers in the image above, we can tell that the top vector in the embedded data set is most like our vector as they are numerically the most similar!
- Context
We then augment the input of the LLM with several pieces;
- The question itself
- The semantic search results
- Chat history
- Pre-amble/instructions to the LLM, such as 'You job is to answer the given question based upon the data provided to you'
- Response
The LLM will then generate a response, and with the augmented input the LLM should give us an accurate, up-to-date and contextually appropriate response
And that's the flow of a basic RAG architecture! We can take a brief look at how we can turn it from basic to advanced, but we'll but we'll save the details for another blog post!
Reliable RAG
RAG Enhancements
Just a quick overview of functionality we can add to improve the reliability of our basic RAG architecture! We'll cover these in more detail in another blog.
- Query Translation
You can't always trust the user to ask the right question, or ask it in the right way. If the question is too specific, then the semantic search may miss chunks that are relevant, if the question is too broad you may involve less relevant chunks which could skew the answer. There are many ways to address this; below are just 3;
- Re-write the query
- Create several alternatives, run several queries simultaneously and combine the results
- HyDE - Hypothetical Document Embedding: Have GenAI produce a hypothetical document that may address the question, and execute the semantic search for that document
- Hallucination Checker
Use a separate checker (a dedicated LLM/prompt/agent) whose job is to read the draft answer and the retrieved context and flag unsupported claims. The flow is simple: generate → check → (optionally) revise or return "no grounded answer." This keeps the answering model fast while the checker enforces groundedness. In practice you’ll score entailment/faithfulness against the retrieved passages and only ship when confidence is high.
- Re-Ranking
Start broad, then sharpen. Do a fast first-pass retrieval, then apply a cross‑encoder re‑ranker to the top candidates so the best 5–10 rise to the top. On Oracle, you can call Cohere Rerank via OCI Generative AI as a managed re‑rank model. The result is higher precision without slowing down ingestion or indexing.
- Retrieval Fusion
Don’t bet on a single retriever. Combine keyword search (BM25) with vector similarity (AI Vector Search in Oracle Database 23ai) and fuse the ranked lists, e.g., with Reciprocal Rank Fusion (RRF). This gives you the best of both!
- Routing
Not every query needs the same path. Add a lightweight router that decides: which collection to hit, whether to use keyword, vector, or both, whether to expand the query, or to skip retrieval entirely. In Oracle, Select AI with RAG lets you keep this logic close to the data, and OCI Generative AI Agents (RAG) can orchestrate multi‑source workflows across enterprise content.
- GraphRAG
Graphs allow you to connect pieces of data together, so you can take a large document, split it into chunks and then connect the chunks. This connection shows a relationship between elements that may not be semantically similar. For example with Harry Potter novel, you may connect Harry Potter with; Hogwarts, Gryffindor, Orphan etc, The idea here is that you still do a vector search to identify semantically related chunks, but then you include related facts that are highly relevant in formulating a response but are not semantically connected...
- Multi‑modal
Often your documents aren't just text, they may have embedded images, tables, scanned text etc and different modalities (image, audio, text, video). To make them searchable, we need to ensure we can embed, search and 'understand' the various formats by utilising multi-modal LLMS (to do, for example OCR) and allow us to execute the same RAG flow on these documents.